VLAN&VXLAN简介 Vlan: 在较大的局域网内,存在多台交换机,多个网段,交换机下的所有主机都处于广播域中,会造成广播风暴,浪费宝贵的带宽资源,通过vlan标签对逻辑子网隔离,划分从逻辑上广播域。 Vlan允许的子网数量为2^12=4096 VLAN环境下不同网段的主机通信必须要经过路由或三层交换来实现。 在云环境中,多租户的场景下VLAN的子网往往是不够使用的,而且VLAN能够解决二层网络中主机之间信道的争抢,但是不能解决三层IP地址的冲突。 因此,为了解决多租户网络重叠(IP地址冲突),产生了VXLAN技术。 VXLAN是一种基于IP网络且采用MAC地址封装在UDP报文中的VPN技术。 VXLAN技术可以通过建立VXLAN隧道,在现有网络架构上建立大量的虚拟可扩展局域网,不同的虚拟可扩展局域网使用VNI(VXLAN Network Identifiler,虚拟可扩展局域网网络标识符)进行标识。 VXLAN提供和VLAN相同的2层网络服务,但相比VLAN拥有更大的扩展性和灵活性,优点如下: 多租户的网络在整个数据中心更具灵活性:VXLAN提供了一个在可靠的共享网络设施上扩展二层网络的解决方案,从而租户的负载(tenant workload)可以在数据中心跨physical pods。 VXLAN提供更多的二层网段,VLAN使用12bit的VLAN_ID表示网段名,从而网段数被限制在4096个,而VXLAN使用24bit作为VXLAN标识符(VNID),使得VXLAN的个数扩展到2^24个。 更好的在基础设施中利用网络路径(Network path):VLAN使用STP(spanning Tree Protocol)协议防止路由环路,最终不使用网络中的网络连接半阻塞冗余路径。VXLAN数据包基于三层报头,可以完整的利用三层路由,ECMP路由以及链路聚合协议来使用所有可用的路径。 传统三层网络: 核心层:核心交换机负责骨干网络传输,对外提供业务。 汇聚层:降低核心交换机的压力,ACL、划分VLAN,控制等都是在汇聚层进行。 接入层:接入到底层的终端服务器。 在南北流量大的场景下,如果东西向流量增多(主机之间通过的层数多),会导致南北向流量拥堵。 VLAN是为解决以太网的广播问题和安全性而提出的一种协议,它在以太网帧的基础上增加了VLAN头,用VLAN ID把用户划分为更小的工作组,限制不同工作组间的用户互访,每个工作组就是一个虚拟局域网。虚拟局域网的好处是可以限制广播范围,并能够形成虚拟工作组,动态管理网络。 GRE VPN(Generic Routing Encapsulation)即通用路由封装协议,是对某些网络层协议(如IP和IPX)的数据报进行封装,使这些被封装的数据报能够在另一个网络层协议(如IP)中传输。 GRE是VPN(Virtual Private Network)的第三层隧道协议,即在协议层之间采用了一种被称之为Tunnel(隧道)的技术。 随手笔记 2019-04-27 评论 3604 次浏览
RabbitMQ RabbitMQ是什么? RabbitMQ是实现AMQP(高级消息队列协议)的消息中间件的一种,最初源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性方面表现不俗。 RabbitMQ主要是为了解决系统之间的双向解耦而实现的,当生产者大量产生数据的时,消费者无法快速消费,那么需要一个中间层保存这个数据。 rabbitmq是一个消息代理,一个消息系统的媒介,它可以为你的应用提供一个通用的消息发送和接收平台,并保证消息在传输过程中的安全。 随着系统压力的增大和系统解耦的急迫性,各大应用之间通过消息队列互相连接起来组成一个更大的应用,并且消息系统通过将消息的发送和接收分离来实现应用程序的异步和解耦。 通过接入rabbitmq解决了数据传递,非阻塞操作和推送通知的操作,实现了发布/订阅、异步处理和工作队列的问题。 RabbitMQ的特点: ①可靠性:RabbitMQ提供了多种技术,可以让使用者在性能和可靠之间进行权衡,这些技术包括持久性机制、投递确认、发布者证实和高可用性机制。 ②灵活的路由: 消息队列到达队列前是通过交换器进行路由的,RabbitMQ为典型的路由逻辑提供了多种交换器类型,如果使用者有更复杂的路由需求,可以将这些交换器组合起来使用,甚至可以实现自己的交换器类型,并当做RabbitMQ的插件来使用。 RabbitMQ提供的内置交换器4中类型中,我们常使用到的有三种,分别是:direct exchange(直连交换器)、topic exchange(主题交换器)、fanout exchange(扇形交换器),RabbitMQ支持多种中间件协议。 ③集群:在相同的局域网中的多个RabbitMQ服务器可以聚合在一起,作为一个逻辑代理来使用。 ④高可用队列:在同一个集群中,队列可以被镜像到多个物理机器中,以确保当中某些硬件故障后消息仍然安全。 ⑤广泛的客户端:只要是能够想到的编程语言,几乎都有与其相适配的RabbitMQ客户端 ⑥可视化管理工具:RabbitMQ给我们提供了易于使用的可视化管理工具,它可以帮助使用者监控信息代理的每一个环节 Direct exchange(直连交换器) 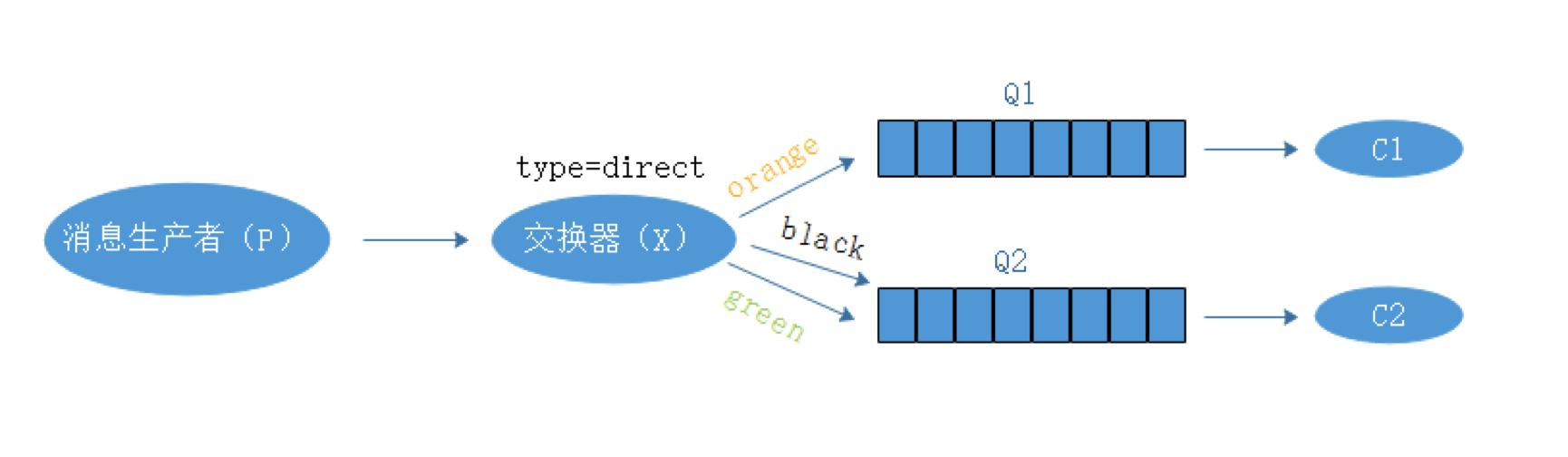 转发消息到routingkey(路由键)指定的队列,routingkey是一个消息的原属性,由生产者加在消息头中。 XQ1 有一个routingkey,routingkey为orange XQ2 有两个routingkey,routingkey为black和green 当消息队列的routingkey(路由键)和routingkey对应时,这个消息去往对应的队列中。 topic exchange(主题交换器) 按规则(通配符)转发消息,这种交换机制下,队列和交换机的绑定会定义一种路由模式,通配符就是要在这种路由模式和路由键之间匹配后,交换器才能够进行消息的转发 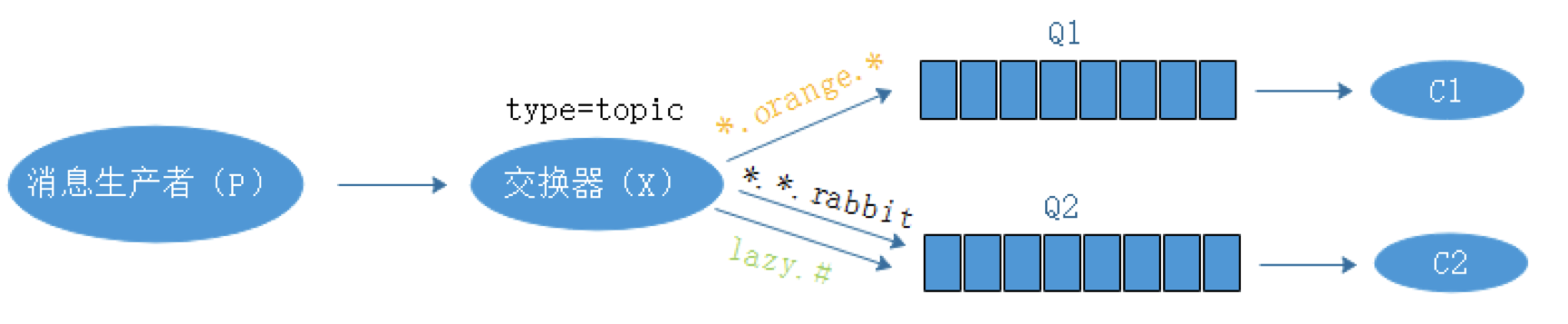 XQ1 有一个路由模式*.orange.*来匹配任何A.orange.B类似的路由键的消息 XQ2 有两个路由模式*.*.rabbit和lazy.#来匹配任何A.B.rabbit和lazy.A、lazy.A.B或者lazy.A.B.C,其中“#”表示一个或多个单词 主题交换器严格区分*.*和lazy.#,在生产环境中尽量不要使用#作为routingkey(路由键) 在指定路由键的时候最好指定准确的路由键作为routingkey fanout exchange(扇形交换器) 转发消息到所有的绑定队列,如果有不同的consumer(消费者)需要对童谣的消息进行不同的处理,使用这种方式是很有用的。 这种类型的交换器,不管是路由键或者是路由模式,会把消息发送给绑定给它的全部队列。 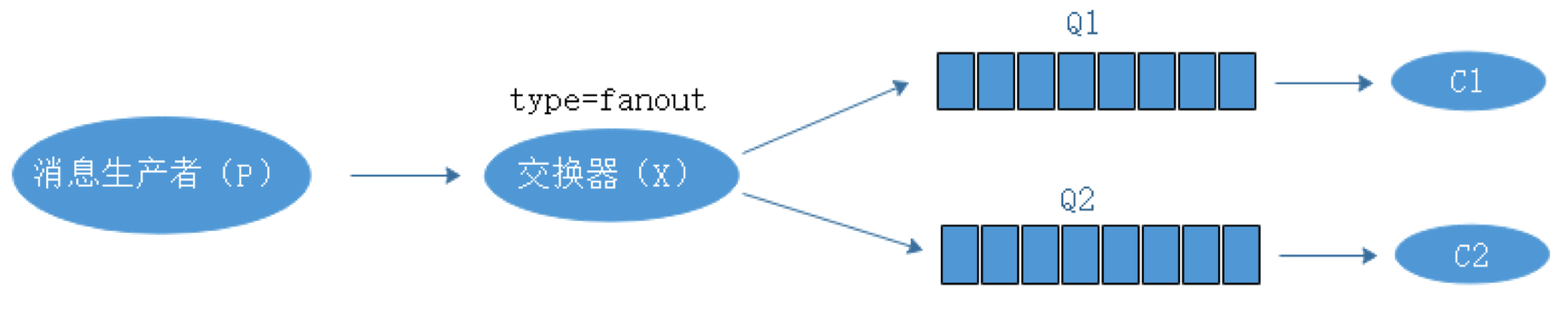 RabbitMQ的模型 RabbitMQ使用的是AMQP协议,这是一种二进制协议,默认启用的端口为5672 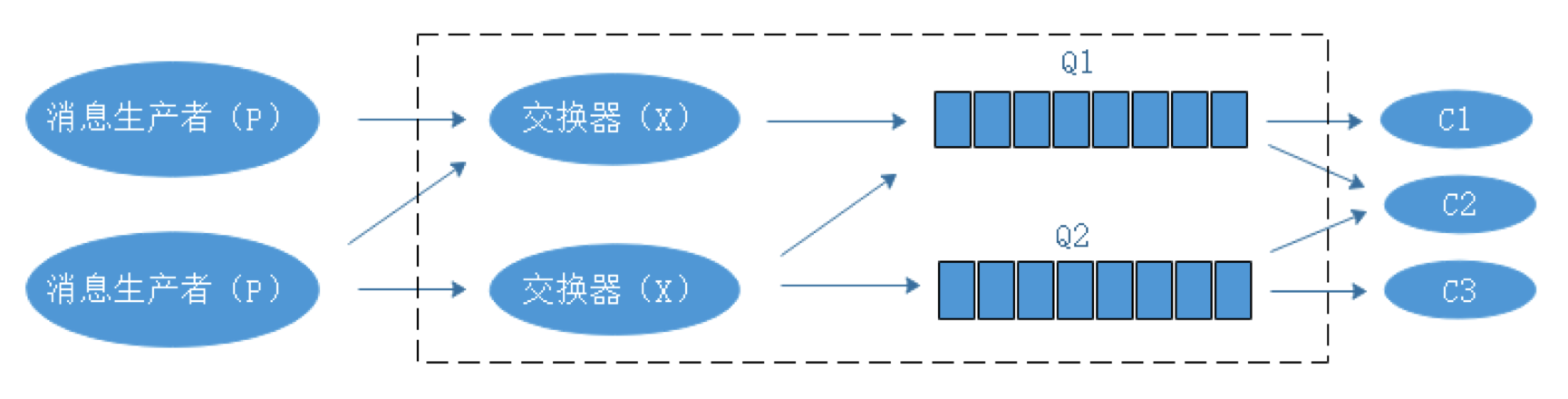 P代表消息生产者,也就是网RabbitMQ发消息的程序 中间件为RabbitMQ,其中包括交换器和队列 C代表消费者,也就是从RabbitMQ拿消息的程序 RabbitMQ的集群 RabbitMQ搭建有三种模式,其中集群模式有两种 ①单一模式 单机情况不做集群,单独运行一个RabbitMQ ②普通模式 默认模式,以两个节点(node_01、node_02)为例来进行说明,对于Queue来说,消息实体只是存在于其中的一个节点(node_01或node_02),node_01和node_02有相同的元数据,即队列结构,当消息进入node_01节点的Queue后,consumer从node_02节点消费时,RabbitMQ会临时在node_01、node_02间进行消息传输,将node_01中的消息实体取出并经过node_02发送给consumer,所以consumer应当尽量连接每一个节点,从中获取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue,否则无论consumer连接node_01或者node_02,出口总在node_01,这样会产生瓶颈,当node_01节点故障,node_02节点无法获取到node_01节点中还未消费的消息实体,如果消息做了持久化,那么就得等node_01节点恢复,然后才可以消费,如果没有做持久化,就会产生消息丢失的现象。 ③镜像模式 把需要的队列做成镜像队列存在于多个节点,属于RabbitMQ的HA方案,该模式下解决了普通模式中的问题,其实和普通模式不同之处在于,消息实体会主动的在镜像节点间同步,而不是在客户端取数据的时候临时拉取,该模式带来的副作用也很明显,除了降低系统的性能外,如果奖项队列数量过多,加之大量的消息进入,集群内部的带宽将会被这种同步通讯大大消耗,所以在对可靠性要求较高的场合中适用。 RabbitMQ集群搭建的注意事项 ①所有机器上,运行的erlang和rabbitmq的版本需相同(否则RabbitMQ之间不能连接到一起) ②所有机器上erlang的cookie需要相同,将/var/lib/rabbitmq/.erlang.cookie复制到其他节点,保证一直,且权限的设置要符合标准(属主属组为rabbiymq) ~]# chown rabbitmq.rabbitmq /var/lib/rabbitmq/.erlang.cookie #修改后需重启服务 两个节点的RabbitMQ集群搭建 搭建epel源,配置主机名DNS解析, ~]# yum install erlang ~]# yum -y install rabbitmq-server ~]# rabbitmq-server -detached #启动 #将/var/lib/rabbitmq/.erlang.cookie复制到其他节点,并修改属主属组 node_01操作: ~]# rabbitmqctl stop_app ~]# rabbitmqctl reset ~]# rabbitmqctl join_cluster rabbit@node_02 #加入node_02集群中 ~]# rabbitmqctl start_app node_02上查看加入集群的状态 ~]# rabbitmqctl cluster_status ~]# netstat -antp #查看rabbitmq之间建立的连接 新增用户: ~]# rabbitmqctl add_user admin 123456 #新添加用户admin,并指定密码123456 ~]# rabbitmqctl set_user_tags admin administrator ~]# rabbitmqctl set_permissions -p / admin ".*" ".*" ".*" #给用户admin授予默认vhost"/"read/write/configure权限 开启图形化管理界面 ~]# rabbitmq-plugins enable rabbitmq_management #访问http://RabbiyMq_Server_IP:15672 #建议使用rabbitmq3.6.9以上的版本和erlang最新的版本 服务 2019-04-27 评论 3449 次浏览
OpenStack组件 IAAS基础设施即服务,面向运维人员 PAAS平台即服务,面向开发人员 SAAS软件即服务,面向用户终端 服务器虚拟化:将一台物理机服务器做成虚拟机 桌面虚拟化:只提供一个桌面,用户的操作限制在桌面 应用虚拟化:采用B/S架构方式实现,但是代价较大 OpenStack:使用Python写的,通过消息队列进行通信,模块化。 Dashboard:管理界面,通过API调用接口。 Dashboard horizon 基于OpenStack API接口使用Django开发的web管理 Compute nova 通过虚拟化技术提供计算资源池 Networking neutron 实现了虚拟机的网络资源管理 Object storage swift 对象存储,适用于一次写入多次读取,写入后不可更改 Block storage cinder 块存储,提供存储资源池 Identity service keystone 认证管理 Image service glance 提供虚拟镜像的注册和存储管理 Telemetry ceilometer 提供检测和数据库采集计量服务 Openstack通过API的方式调用服务,REST API 调用的方式: curl、firefox plugin、restclient-ui-3.4-jar(java写的在Windows下的工具) 只要能够支持HTTP协议就能够进行调用 Xshell用户信息添加页面上可以对远端主机进行端口的映射(通过22端口将远端服务器端口映射到本地:127.0.0.1:xxxx) 查询请求:get 修改请求:put 云平台的部署要根据用户的需求对各个组件进行选择,参照需要启动多少实例,实例的配置,镜像的数量等对硬件需求进行规划。在生产环境中安装使用种子节点的方式,既作为控制节点又作为种子节点,使用PXE对镜像和软件进行推送。 部署openstack的顺序: ①安装控制节点操作系统和网络配置 ②控制节点安装必要的中间件和相关系统服务 ③控制节点组件安装 ④(SDN)网络节点操作系统安装 ⑤(SDN)网络节点安装必要的中间件和相关系统服务 ⑥(SDN)网络节点组件安装 ⑦计算节点操作系统安装 ⑧计算节点安装必要的中间件和相关系统服务 ⑨计算节点组件安装 CentOS_7上安装OpenStack注意事项: 采用本地yum源构建速度会快很多,可以使用FTP服务器提供服务 关闭NetworkManager 关闭firewalld 关闭selinux 设置主机名并搭建DNS,可以使用host解析,也可使用bind提供服务,controller上搭建 搭建时间服务器,在控制节点上安装。 注意:openstack使用主机名来进行区分,如果某节点主机名被修改会造成不可逆的操作。 OpenStack网络示意图 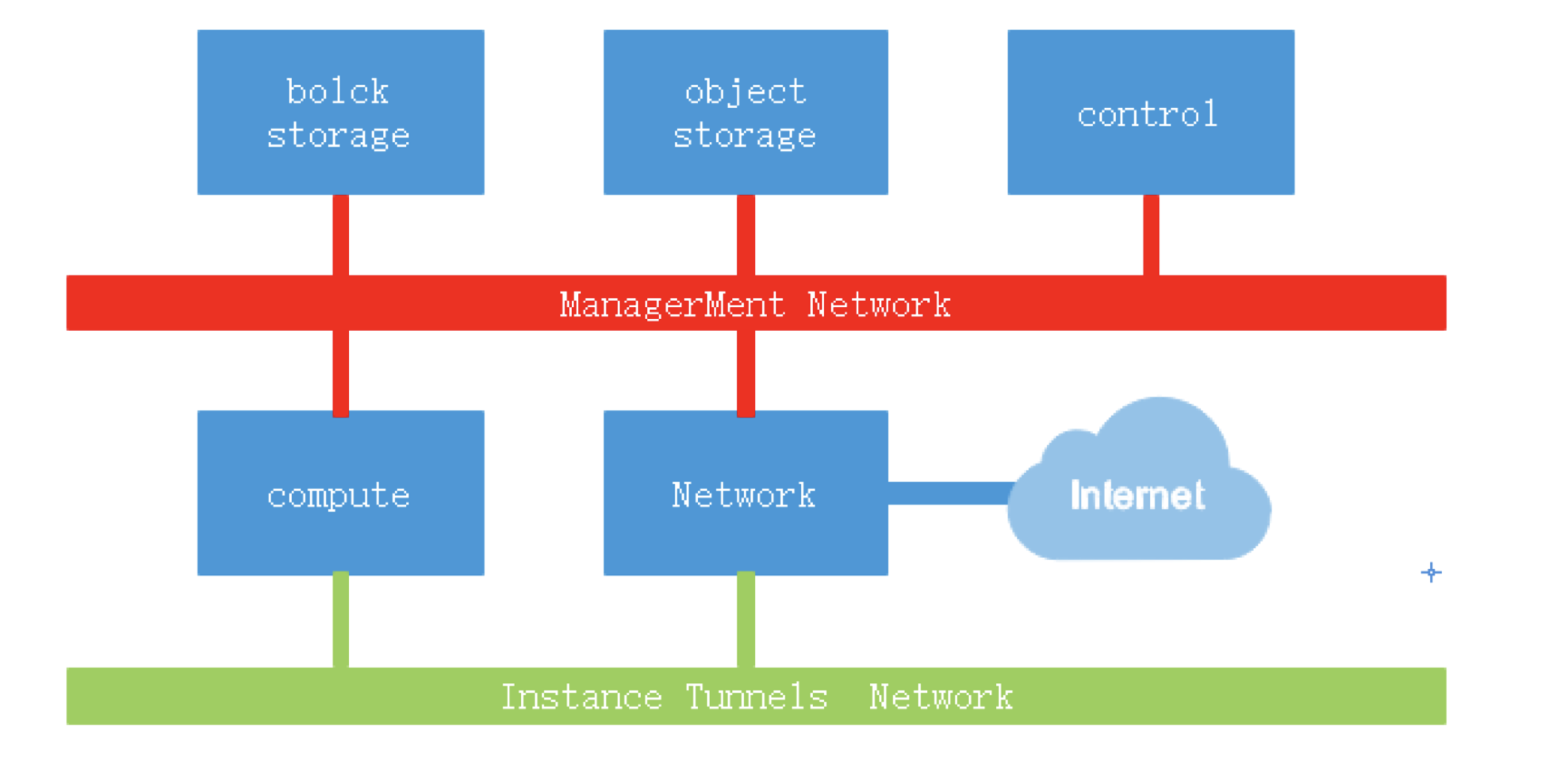 Keystone验证流程: 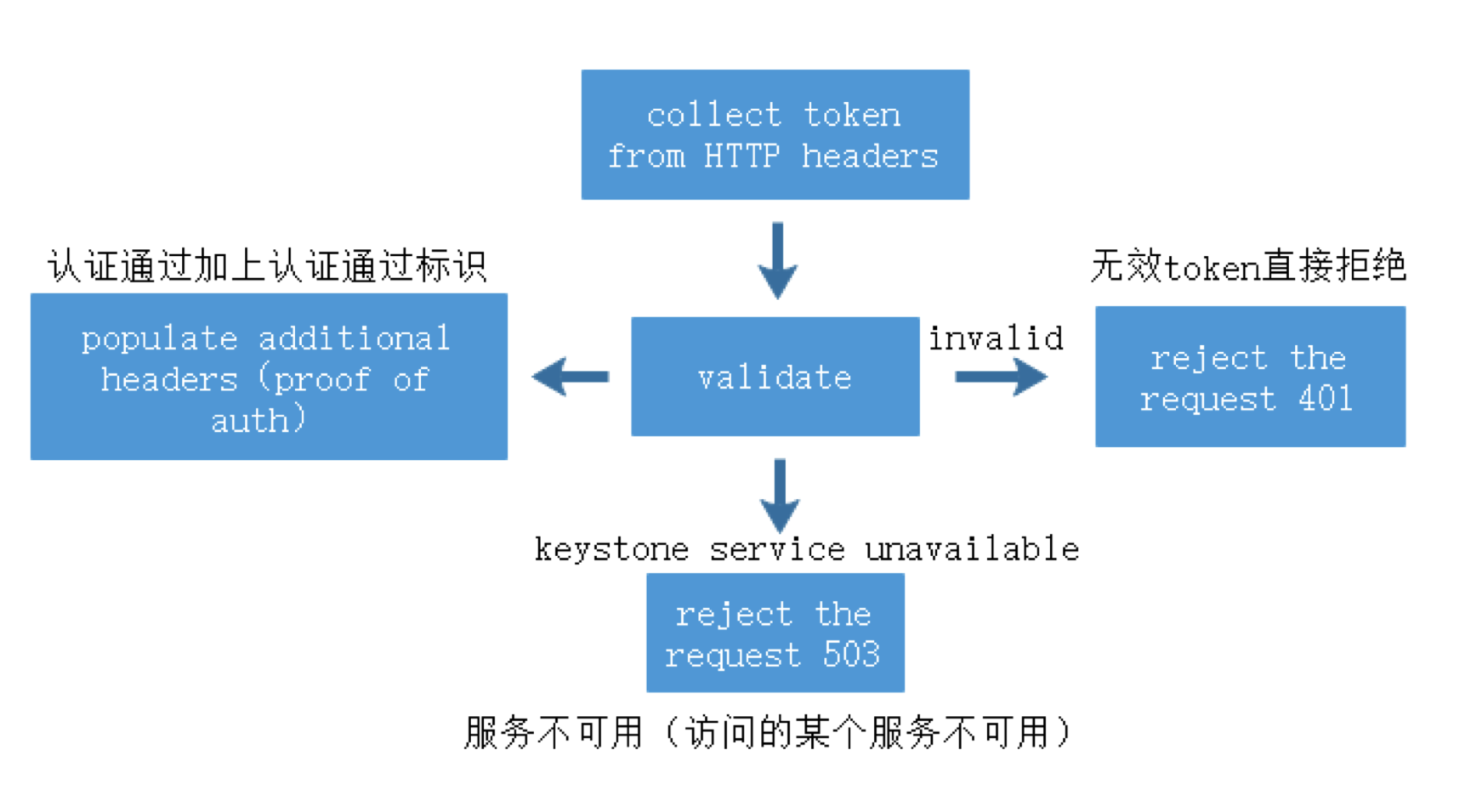 用户创建虚拟机的流程: 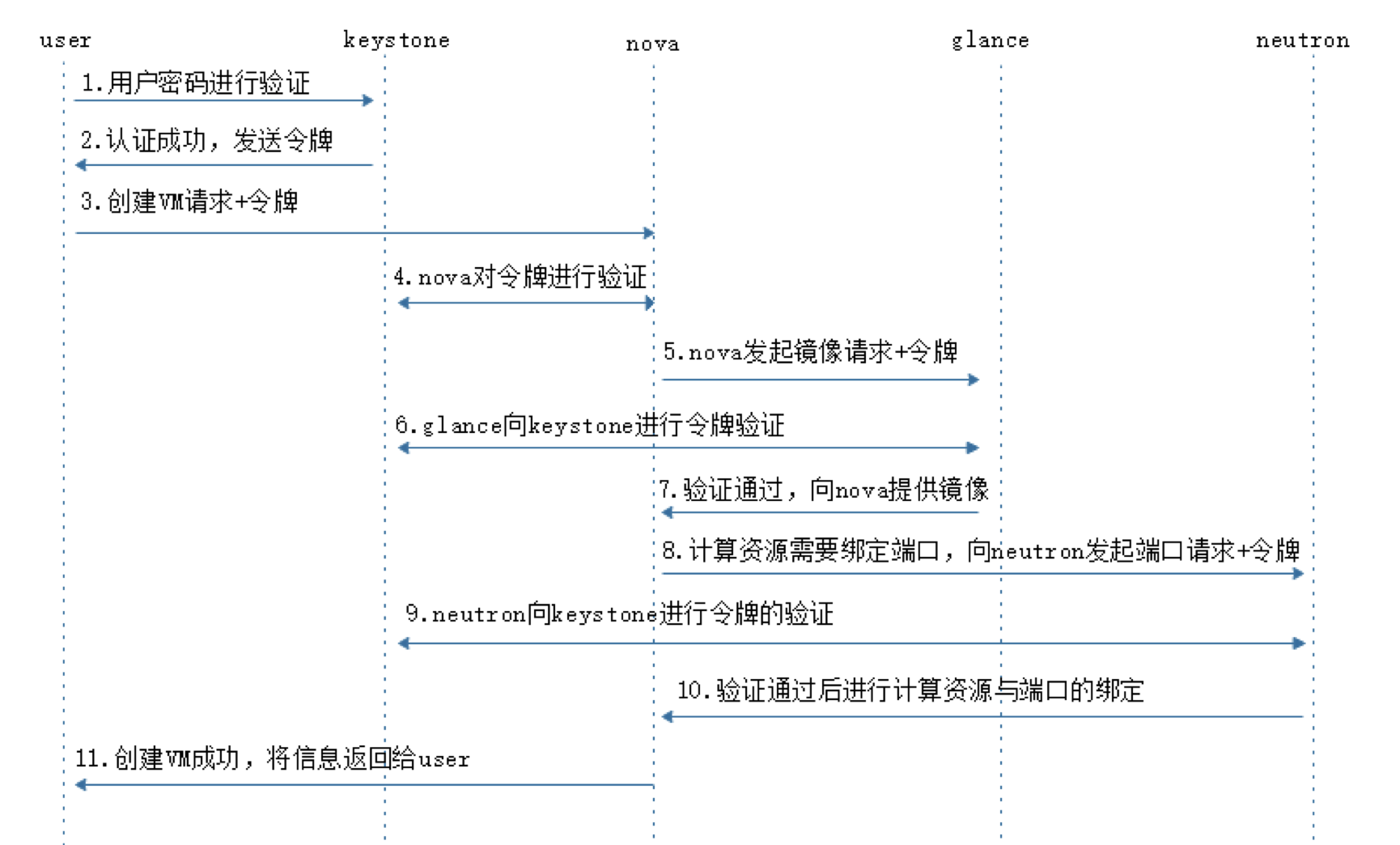 ~]# keystone token-get #以当前用户身份获取一个token Openstack平台搭建的时候租户、用户、角色的创建流程: 先创建租户 创建用户时指定属于那个租户 创建角色,默认有两个角色:admin(管理员),member(普通用户),角色可自定义 绑定角色,将角色分配到具体的某个用户,这个用户在这个租户下是什么角色 镜像-glance Image identifiers Image_URI(<glance server location>/images/<ID>全局唯一的定位符) Image status(对镜像操作的状态) Queued:镜像已经被保留(metadata已经写入数据库,但是还没有上传镜像。) Saving:镜像正在被上传 Active:镜像可以使用 Killed:镜像损坏或者不可用 Deleted:镜像被删除(只有拿着被删除的镜像的ID去查找的时候才会出现,在dashboard上不会显示。) Disk format: Raw:裸数据,二进制组成,占用磁盘较大,启动虚拟机较快。 Vhd:vmware、xen、microsoft、virtualbox支持的格式 Vmdk:vmware发起的开源的磁盘格式 Vdi:virtualbox、QEMU、emulator支持 Iso:主要是归档使用 Qcow2:用于kvm虚拟机上,磁盘支持扩展,磁盘动态变化、支持快照 Container format(容器格式): Bare:裸格式 Ovf:虚拟机格式,使用较多 Glance API用于处理HTTP请求 Glance_DB:metadata for image,存储镜像的元数据信息 Store adapter:image的存储方式由store image决定,通常我们是用文件系统的方式进行存储。 存储的方式可以是filesystem、swift storage、S3(simple storage servers) 亚马逊镜像的存储方式、HTTP storage(也可以将镜像放到HTTP服务器上)。 RDB:ceph(分布式块存储)等存储方式。 Glance镜像的定制: 定制的需求: 包的添加与删除 Linux的优化 支持秘钥登录等预设定功能 首先到官网下载能在openstack上使用的镜像 1. 先创建一个10G的文件 ~]# qemu-img create –f qcow2 image-test.img 10G 对于创建好的文件可以使用file命令查看文件的类型 2. 创建虚拟机 ~]# virsh-install --name VM_NAME --hvm –ram 2048 --vcpus 4 –disk path=/var/tmp/image-test.img size=10,bus=virtio,format=qcow2 --network network:default --acclerate --vnc --vncport=5908 --cdrom /var/tmp/centos-xx-xx.iso -boot cdrom xhell想要看到虚拟机内的图形界面,需要在xshell中开启x11隧道转发(需要manager)通过22端口。 启动起来的操作系统删除网卡的MAC、UUID等硬编码信息(70的配置文件) 禁用防火墙,清空/etc/sysconfig/iptables中的规则信息 默认启用SSH服务 开机自动resize根分区 设置使用SSH密钥对连接 设置YUM源 ~]# yum -y install cloud-init #针对云的运行环境需要使用到的一些功能 ~]# vi /etc/cloud/cloud.conf #通过更改该配置文件可以定义instance启动起来后的一些行为。 ~]# shotdown -h now #修改完成关机,此时需要注意的是不能开机,否则需要重新修改。 将imag-test.img作为镜像上传至glance服务器,镜像制作完成。 使用virtualbox也能够完成镜像的制作 创建vmdk格式的硬盘文件的虚拟机 安装操作系统并进行相应的修改,关机 将vmdk文件上传到Linux主机上进行格式的转换 ~]# qemu-img convert -f vmdk -O raw CentOS_6.vmdk CentOS_6.img #现将vmdk格式的镜像转成raw格式,不能直接转成qcow2的格式 ~]# qemu-img convert -f raw -O qcow2 CentOS_6.img CentOS_6.qcow2 ~]# qemu-img info 镜像名称 #查看镜像的信息 修改镜像中的内容: 使用guestfish工具,需要先安装 ~]# guestfish --rw -a 镜像名 进入guestfish工具环境 >run 启动镜像 >list-fliesystems 3查看磁盘及文件系统类型 >mount /dev/sda1 / #将root挂载到根上 >upload 本地文件 镜像目录下的文件 #上传文件到镜像中,徐志鼎镜像中的文件名,不能自动生成 >download 镜像文件 本地目录下的文件 #将镜像中的文件下载到本地 安装软件等操作不适合在此处进行。 nova核心组件: controller节点组件: nova-api 接口,用于接收http请求 nova-schedule 计算资源调度 nova-conductor 连接数据库的Proxy(避免直连数据库,大量的直连导致数据库的压力无法均衡) nova-conductor 认证 nova-novncproxy vnc proxy(避免直接访问vnc) compute节点组件: nova-compute 负责虚拟机的管理 client: nova-client 向nova发起请求的客户端 nova-manage 运维组件管理操作工具 nova主要是提供计算服务,大致服务框架如下: 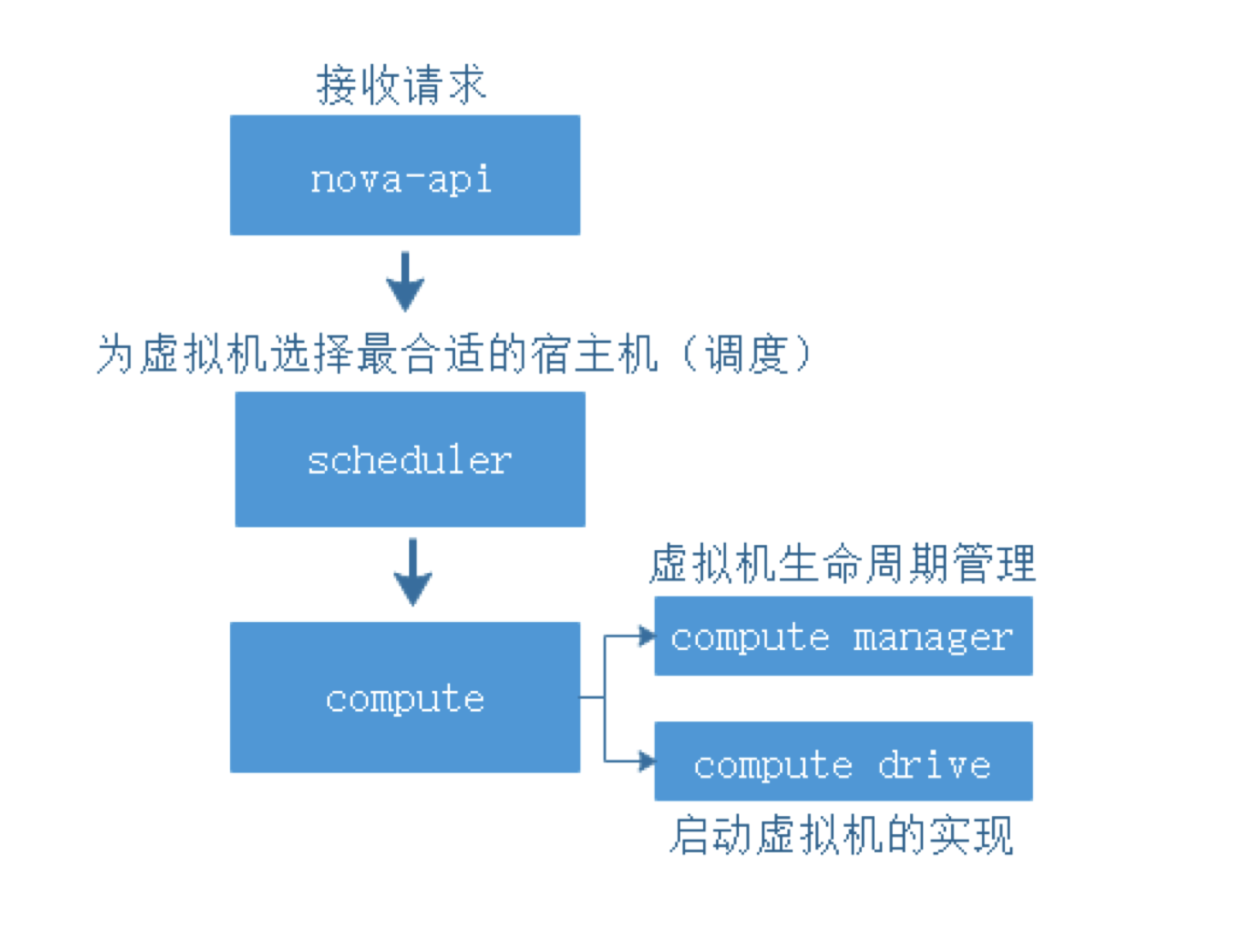 nova内部组件的交互: 采用RabbitMQ Queues(消息队列),异步通信,组件之间是松耦合关系。 如果采用API的方式,强耦合使得服务的拆解变得困难。 对应的服务只需要监控消息队列,即可完成消息的获取。 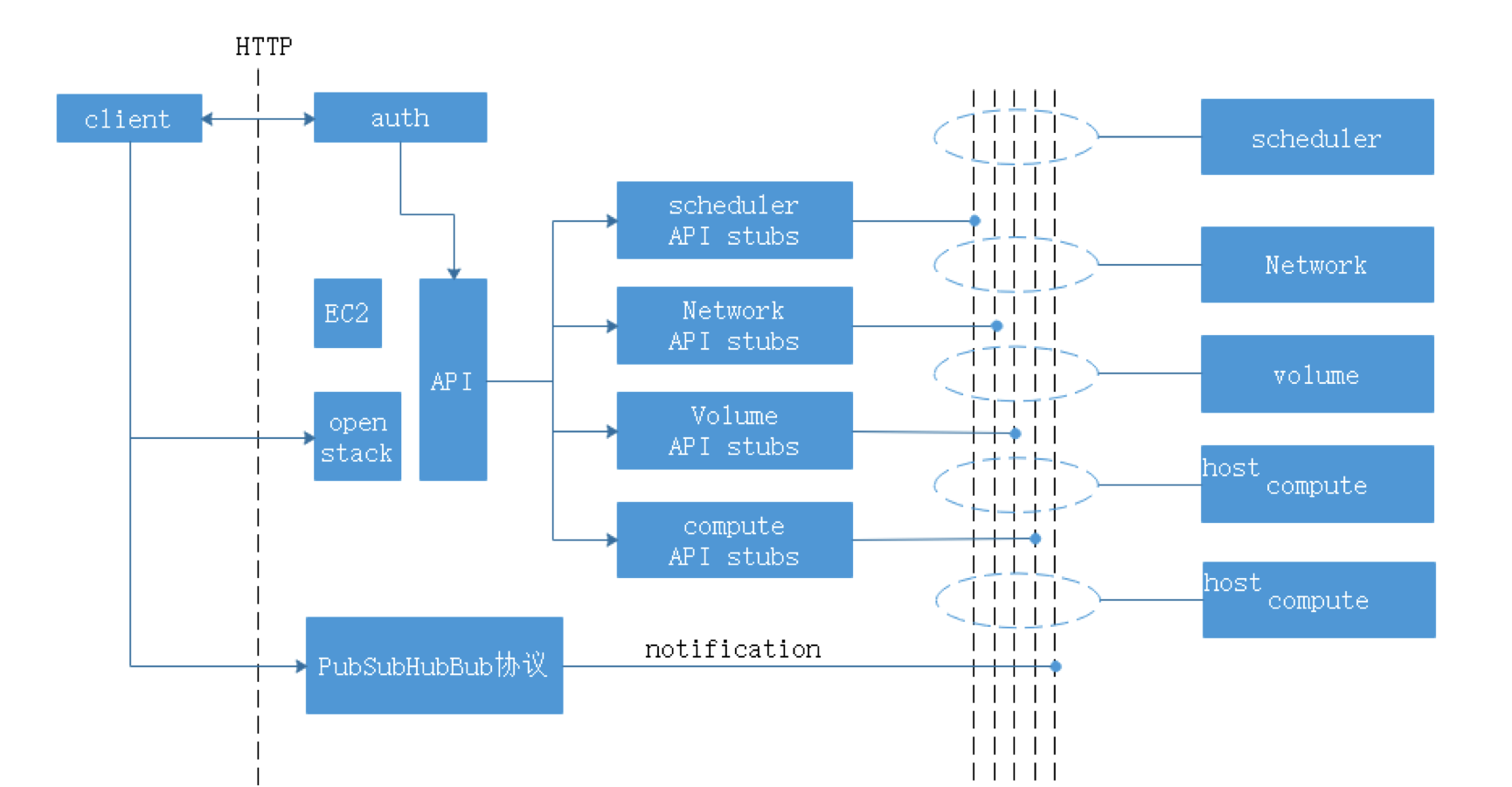 nova启动innstance的流程,涉及两个节点: nova:cloud controller nova:compute node 以及其他公用的组件,如glance、swift等 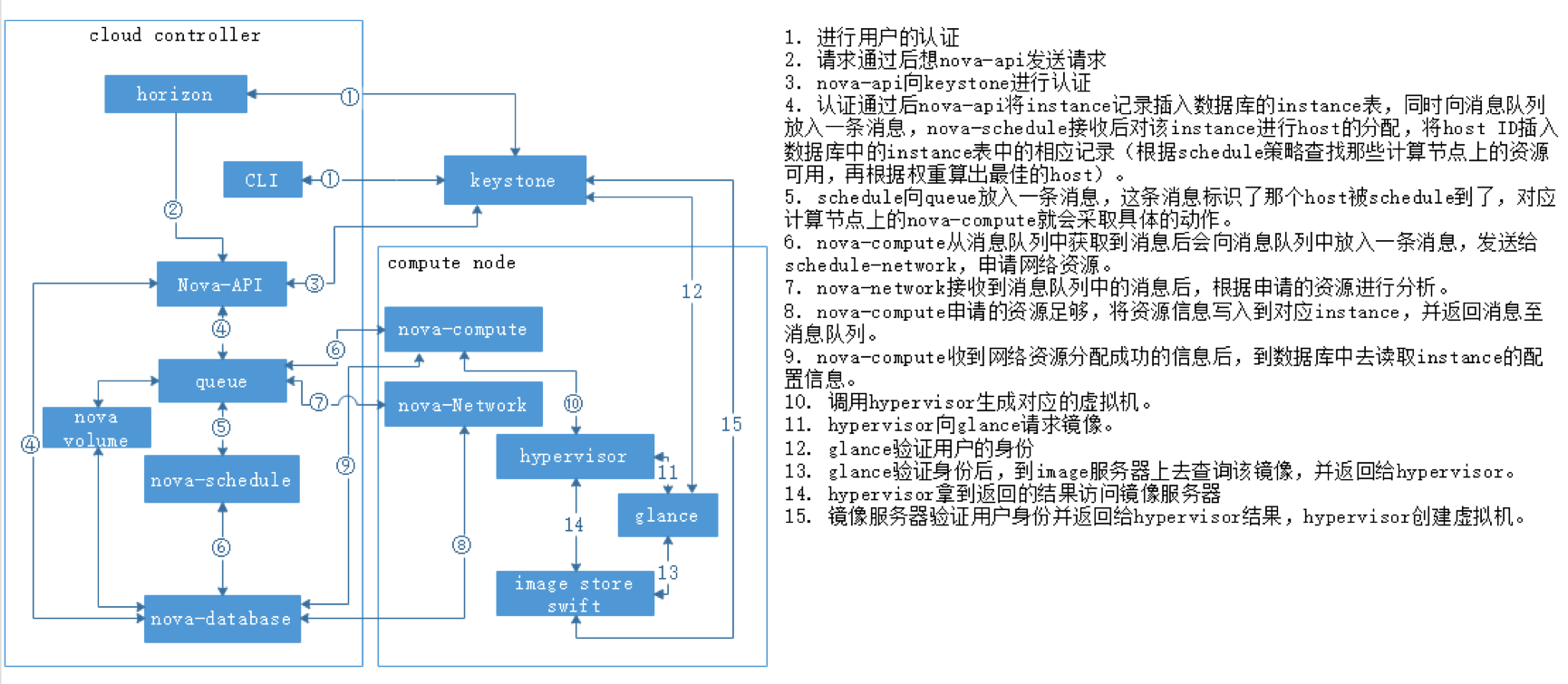 ~]# virsh list --all #查看当前计算节点上的实例 ~]# virsh edit Instance_ID #显示指定实例的VNC端口号 ~]# cd /var/lib/nova/instance/ #该目录下是以虚拟机ID命名的目录,实例启动后存放磁盘的目录。 console.log 启动过程日志 disk 虚拟机的磁盘 libvirt.xml instance描述文件 ./base 为glance下载的镜像 ~]# virsh vncdisplay Instance_ID #显示指定实例的VNC端口号 ~]# qumu-img info /var/lib/nova/instance/base/Image_File #查看镜像文件格式 创建虚拟机常见的错误: 401:认证错误 检查用户名密码是否输入正确 检查认证配置是否正确 409:查看nova服务是否正常运行 No Valid host错误 查看是不是有可用的资源(compute节点) 调高配置资源,或者删除一些无用的主机。 网络不通: 查看dhcp(dnsmasq)、查看路由、查看openswitch服务是不是crash。 查看instance启动流程 编辑计算节点下配置文件 ~]# vim /etc/nova/nova.conf #开启debug,并开启日志 ~]# /etc/init.d/openstack-nova-api restart #重启nova-api服务 OpenStack网络: LInux interface type: TAP/TUN kvm等Hypervisor虚拟网卡的实现 TUN and TAP device have 啊/sys/class/net/tap0/tun-flags file bridge 相当于交换机,所有的物理网卡收到的包都是一样的,每个网卡只抓取自己的数据包 brideg have a /sys/class/net/br0/bridge directory loopback 回环网卡 bridge and loopback interface have 00:00:00:00:00:00 in /sys/class/net/lo/address physical 物理网卡 physical device have a /sys/class/net/eth0/device symlink floast IP(浮动IP)的实现需要物理网卡开启混杂模式(promiscuous mode) "UP BROADCAST RUNING MULTICAST" 网卡信息中显示此条信息表示已开启混杂模式。 依靠dnsmasq服务实现DHCP功能 DNSmasq是一个小巧且方便地用于配置DNS和DHCP的工具,适用于小型网络,它提供了DNS功能和可选择的DHCP功能。它服务那些只在本地适用的域名,这些域名是不会在全球的DNS服务器中出现的。DHCP服务器和DNS服务器结合,并且允许DHCP分配的地址能在DNS中正常解析,而这些DHCP分配的地址和相关命令可以配置到每台主机中,也可以配置到一台核心设备中(比如路由器),DNSmasq支持静态和动态两种DHCP配置方式。 LXC:Linux Container容器是一种内核虚拟化技术,可以提供轻量级的虚拟化,以便隔离进程和资源。网络隔离,主机上可以配置多个相同IP地址或相同网段的网卡。 叠加网络: 1. 一个数据包封装在另一个数据包内,被封装的包转发到隧道断电后在进行拆装。 2. 叠加网络就是使用这种"包内之包"的技术安全的将一个网络隐藏在另一个网络中,然后将网络区段进行迁移。 VLAN:L2 over L2 GRE:L3 over L3(UDP) VXLAN:L2 over L3(UDP) atp设备: tap设备是kvm虚拟机网卡的实现类型,虚拟机可以通过tap设备和连接在另一端的设备进行通信。 tap设备的查找方式: ~]# cat /etc/libvirt/qumu/instance-XXX.xml #虚拟机xml文件 可以在xml文件中看到<target dev='tapb……'/> 虚拟网络对(VETH,Virtual Ethernet Pair) 将两个网卡直接连接起来,在一端发怵消息,在另一端可以完整的收到,类似于网线的作用,用于连接bridge和switch(不同虚拟网之间的连接)。 虚拟网络对(VETH)设备的查看: ~]# ip a ~]# ethtool -S 设备名 #可以看到成对的VETH设备的index编号是连续的,即成对出现。 Linux Bridge的使用 bridge相当于HUB设备,转发接收到的数据包到所有端口 bridge的查看方式: ~]# brctl show #网桥上有两个设备,一个是连接虚拟机的tap设备,一个是连接open switch的虚拟网卡对,也可以通过虚拟机的xml文件进行查看。 #] cat /etc/libvirt/qemu/instance-xxx.xml #体现在interface标签中 neutron SDN实现: neutron SDN的实现是在计算节点和网络节点上实现的。 实例通过tap设备连接到br-int(open vswitch bridge) 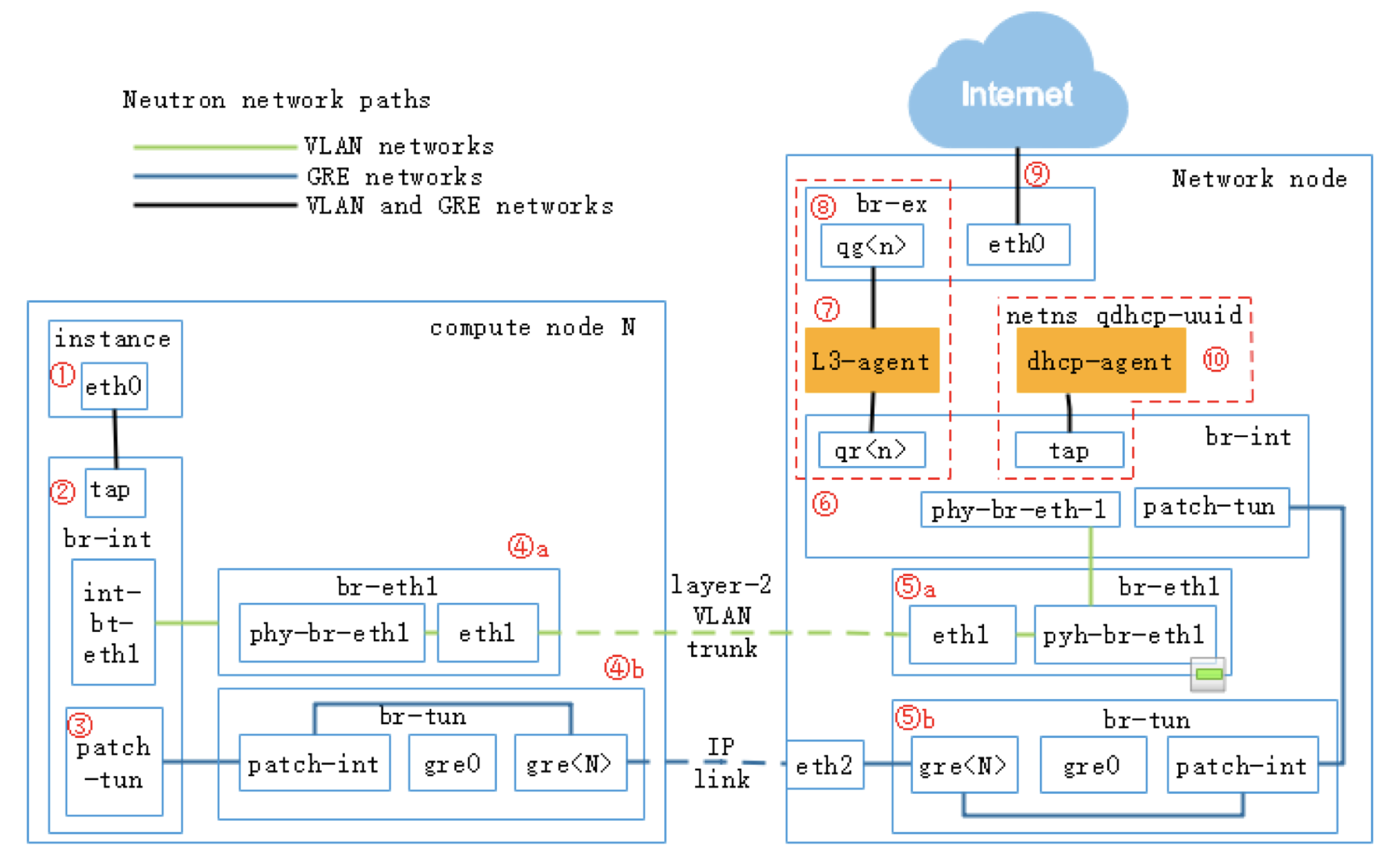 neutron SDN GRE的实现 br-int与br-tun之间由虚拟网络对连接(patch-tunpatch-int),br-tun是专门用于同其他主机建立隧道的bridge,数据通过建立的隧道到达Network node节点的br-tun(通过指定IP到达),br-tun通过虚拟网络对连接(patch-intpatch-tun)br-int,在network上的br-int上有一个特殊的网口qrXX,它属于br-int网桥,同时它暴露在物理层,连接到br-ex的qgXX,图中红色虚线为同一个namespace,namespace中配置了source NAT规则,在同一个网桥下的eth0物理网卡收到数据包,并将其转发到Internet。 计算节点网络的实现 open switch的使用: 在open switch上可以配置端口和VLAN ~]# ovs-vsctl show #每创建一个虚拟机都会多出四个虚拟网卡 #在compute节点上,网桥以qb开头(连接虚拟机的bridge),q为前一代网络组件名称的简写。 虚拟网络对的识别: qvo:连接到open vswitch qvb:连接到bridge 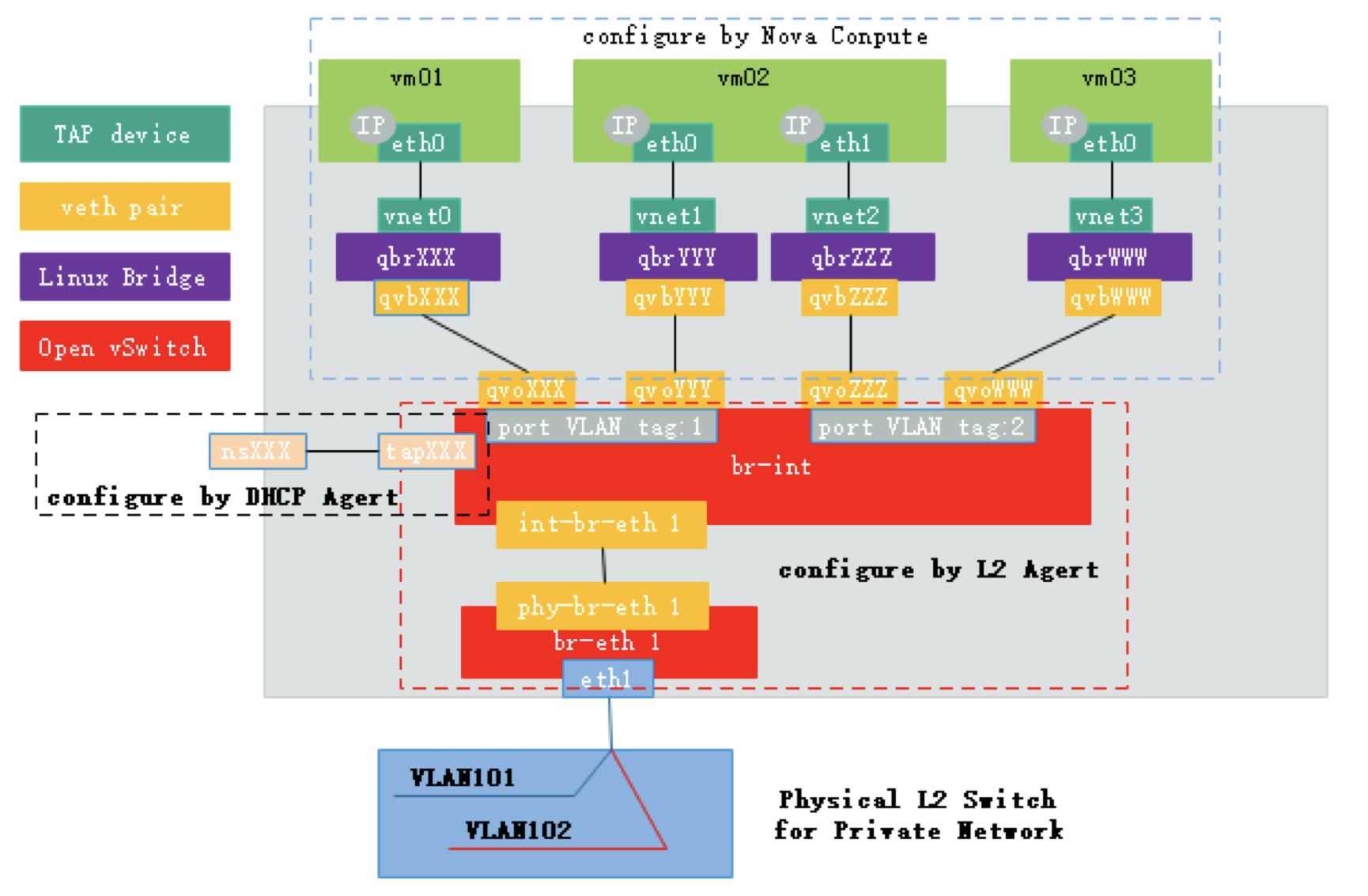 虚拟机的网卡是由tap设备提供的,tap设备的另一端连接到Linux网桥上,再由虚拟网络对连接到open vswitch,从此tap设备出来的数据包会带有port VLAN tag标记。因此,不同的虚拟机如果属于同一个子网,port ID是一样的,再通过虚拟网络对从open vswitch连接到open vswitch的bridge上,这个bridge是直连物理网卡的,因此和外网是通的,在此处(bridge)会将虚拟机的VLAN转换成物理机的VLAN_ID 网络节点network ~]# ovs-vsctl show #查看open vswitch的网络状态 #当open vswitch接收到数据包的时候会将数据包转发给相同tag标记的port #此处显示的tap设备是DHCPserver的网卡 ~]# ip netns #可以看到3个namespace(一个网络中) #qrouter用于路由,该命名空间中有相应网段的网关(web界面上需要使用amdin查看,因为网络是admin创建的) #namespace名称的后缀是网络的ID ~]# ip netns exec NameSpace ip a #查看namespace中的内容,可以找到与DHCPserver先关的tap设备,因此命名网络空间中的tap设备就是DHCPserver ~]# ps -ef |grep dnsmasq #可查看相关进程,DHCP服务器进程 ~]# ip netns exec qrouterXXX route #W查看命名空间中的路由表 ~]# ip netns exec qrouterXXX iptables -t nat -nL #查看命令空间中的NATO转发规则 OpenStack+Ceph 2019-04-27 评论 6653 次浏览
OpenStack+Ceph在Ceph底层删除卷——慎用!建议从OpenStack层面进行删除操作。 我门在删除云平台快照的时候,会遇到快照被依赖的情况,这个时候可能在openstack层面删除不掉,需要从ceph底层解决: ``` ~]# rbd snap rm volumes/volume-db3aee3c-b549-48d9-8cdc-65a801845c6c@snapshot-dd42a722-be84-4792-8557-e50b1aaa2b05 Removing snap: 0% complete...failed. rbd: snapshot 'snapshot-dd42a722-be84-4792-8557-e50b1aaa2b05' is protected from removal. ~]# rbd children volumes/volume-db3aee3c-b549-48d9-8cdc-65a801845c6c@snapshot-dd42a722-be84-4792-8557-e50b1aaa2b05 ~]# rbd snap unprotect volumes/volume-db3aee3c-b549-48d9-8cdc-65a801845c6c@snapshot-dd42a722-be84-4792-8557-e50b1aaa2b05 ~]# rbd snap rm volumes/volume-db3aee3c-b549-48d9-8cdc-65a801845c6c@snapshot-dd42a722-be84-4792-8557-e50b1aaa2b05 ``` OpenStack+Ceph 2019-04-25 评论 4281 次浏览
OpenStack+Ceph云平台卷清理操作 云平台运维:openstack+ceph 卷清理: #####建议使用openstack环境的命令来进行删除,如非必要不适用ceph的底层命令来进行卷的删除。 ``` 先source授权文件,或者自行声明 export OS_PROJECT_DOMAIN_NAME=Default export OS_USER_DOMAIN_NAME=Default export OS_PROJECT_NAME=admin export OS_TENANT_NAME=admin export OS_USERNAME=admin export OS_PASSWORD=PassWord export OS_AUTH_URL=http://IP:35357/v3 export OS_INTERFACE=internal export OS_IDENTITY_API_VERSION=3 export OS_REGION_NAME=RegionOne export OS_AUTH_PLUGIN=password ``` ``` cinder snapshot-show Snap_Name #查看快照 cinder snapshot-delete Snap_Name #删除快照 ``` 注意!!卷被锁住的情况,需要将卷先解锁,再将卷进行删除。 ``` ~]# rbd lock list Pool_Name/Volume_Name ~]# rbd lock remove Pool_Name/Volume_Name ``` 在dashboard界面上查看需要处理的【卷ID】、【快照ID】 ceph_mon容器中进行操作: ``` ~]# rados lspools #查看ceph集群中有多少个pool ~]# rbd ls -l -p Pool_Name |grep 【ID】 #查看ID是否过滤出来 ~]# rbd snap purge Pool_Name/Volume_Name #清除指定镜像的所有快照 #如果清除失败会给出快照的名称,使用此名称进行操作 ~]# rbd snap unprotect Pool_Name/Volume_Name@Snapshot_Name #移除保护状态 如果移除失败,在数据库中查看该快照是否还创建了其他卷。 ~]# mysql -uroot -pPassWord >use cinder; >select * from volumes where snapshot_id='a4eb968e-b068-4d0d-be70-9faec40a6e8e'\G; #通过快照ID查看是否还有卷关联 #一般情况下存在状态为in_use的状态的卷相关联。 >select * from volumes where id='e4568665-bde3-47dd-8748-18f8362a9345'\G; #查看卷的名称是否可以删除,如可以删除则删除。 #如果卷不能删除,则将把快照的信息复制给子克隆,拍平子镜像 ~]# rbd flatten Pool_Name/Volume_Name ~]# rbd snap purge Pool_Name/Volume_Name #再次清除指定镜像的所有快照 ~]# rbd rm Pool_Name/Volume_Name #删除指定卷 #当删除成功后,更改数据库中的内容(需要更改两处内容) #我们不能直接删除数据库中的内容,而是更改数据库中的对应的值。 >set foreign_key_checks=0; #关闭数据库的外键约束 >update volumes set status='deleted' where id="8b63779e-0619-4353-876b-499ea1f68b8f"; #更改状态为已删除 >update volumes set deleted=1 where id="8b63779e-0619-4353-876b-499ea1f68b8f"; #更改删除状态为1(已删除) >set foreign_key_checks=1; #开启数据库的外键约束 ``` dashboard界面刷新快照闪现(或者删除快照),修改数据库两处内容: ``` >use cinder; >show tables; >describe snapshots; >select * from snapshots where volume-id='Volume_ID'; >set foreign_key_checks=0; #临时关闭外键依赖 >update snapshots set status='deleted' where volume_id='Volume_ID'; >update snapshots set deleted=1 where volume_id='Volume_ID'; >set foreign_key_checks=1; #开启外键依赖 ``` 注:deleted的值:1为删除、0为可用 OpenStack+Ceph 2019-04-25 2 条评论 12200 次浏览
OpenStack+Ceph磁盘解锁 虚拟机启动不了,报磁盘IO错误的解决办法 可能是Ceph底层卷被锁住了 首先查看云平台问题主机的磁盘ID,如果是磁盘被锁住在Ceph节点上进行解锁操作: ``` ~]# rbd lock list Pool_Name@Valume_Name There is 1 exclusive lock on this image. Locker ID Address client.2913395 auto 94177727959424 10.0.100.204:0/730917960 ~]# rbd lock remove Pool_Name@Valume_Name "ID" Locker ~]# rbd lock rm volumes/volume-1c1a4056-3f45-4217-aaf1-7db823857c4f "auto 94177727959424" client.2913395 ``` 注:ID可能是空格隔开的字符串,需要使用双引号引起来 OpenStack+Ceph 2019-04-25 2 条评论 12500 次浏览
